Lead Scoring Case Study
- Tech Stack: PySpark, AWS
- Github URL: Project Link
- Presentation: Case Study Analysis
📑 Overview This project focuses on improving lead conversion rates for X Education Company, aiming to increase their current conversion rate from 30% to an ambitious 80%. We leveraged logistic regression to identify high-potential leads and enhance the overall lead conversion process.
🎯 Project Objectives
- Identify High-Potential Leads: Develop a model to score leads based on their likelihood to convert.
- Enhance Conversion Rates: Refine the lead conversion process to achieve a target rate of 80%.
🚀 Approach
- Data Cleaning: Addressed missing values, outliers, and irrelevant columns while transforming categorical variables.
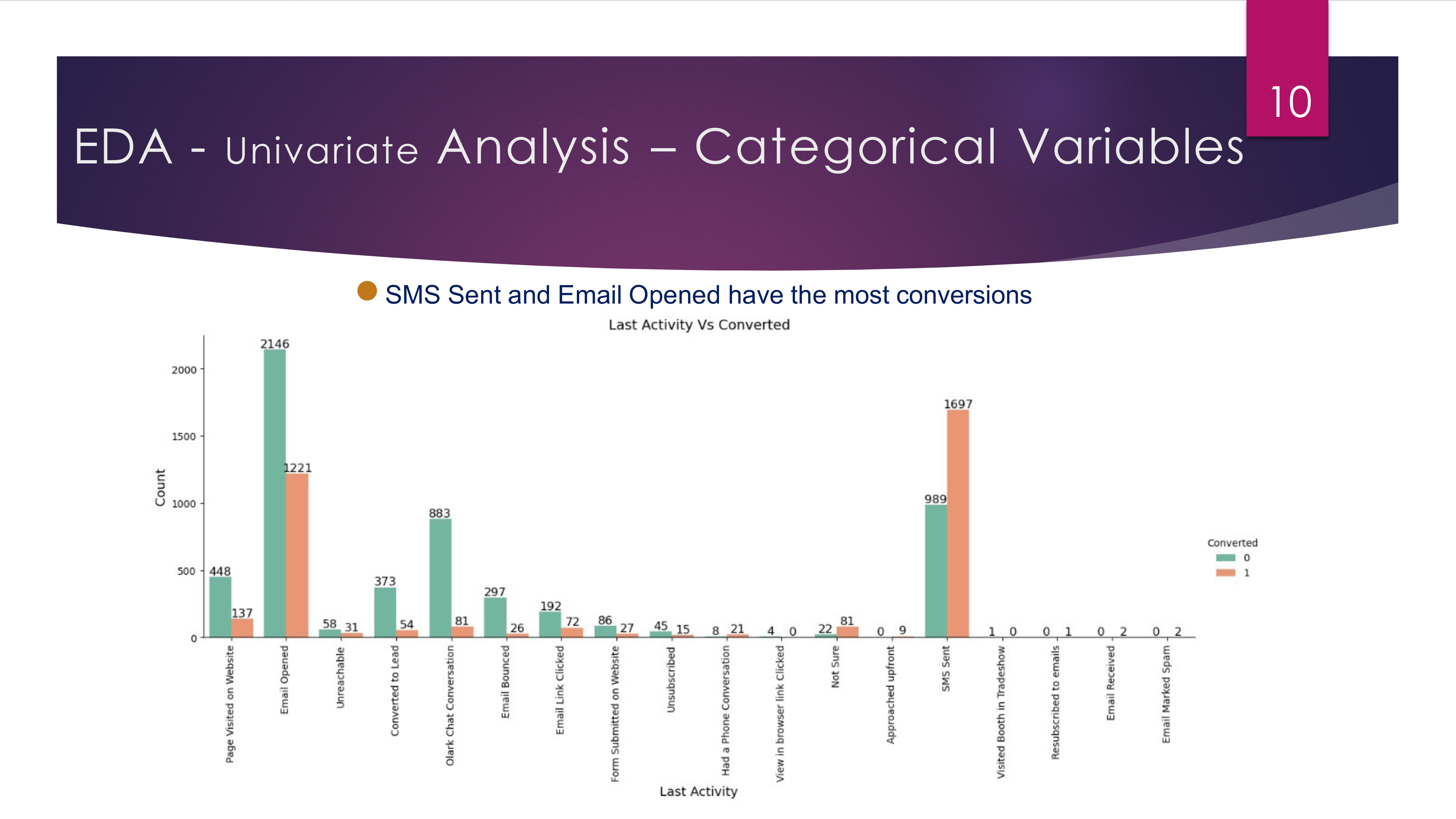
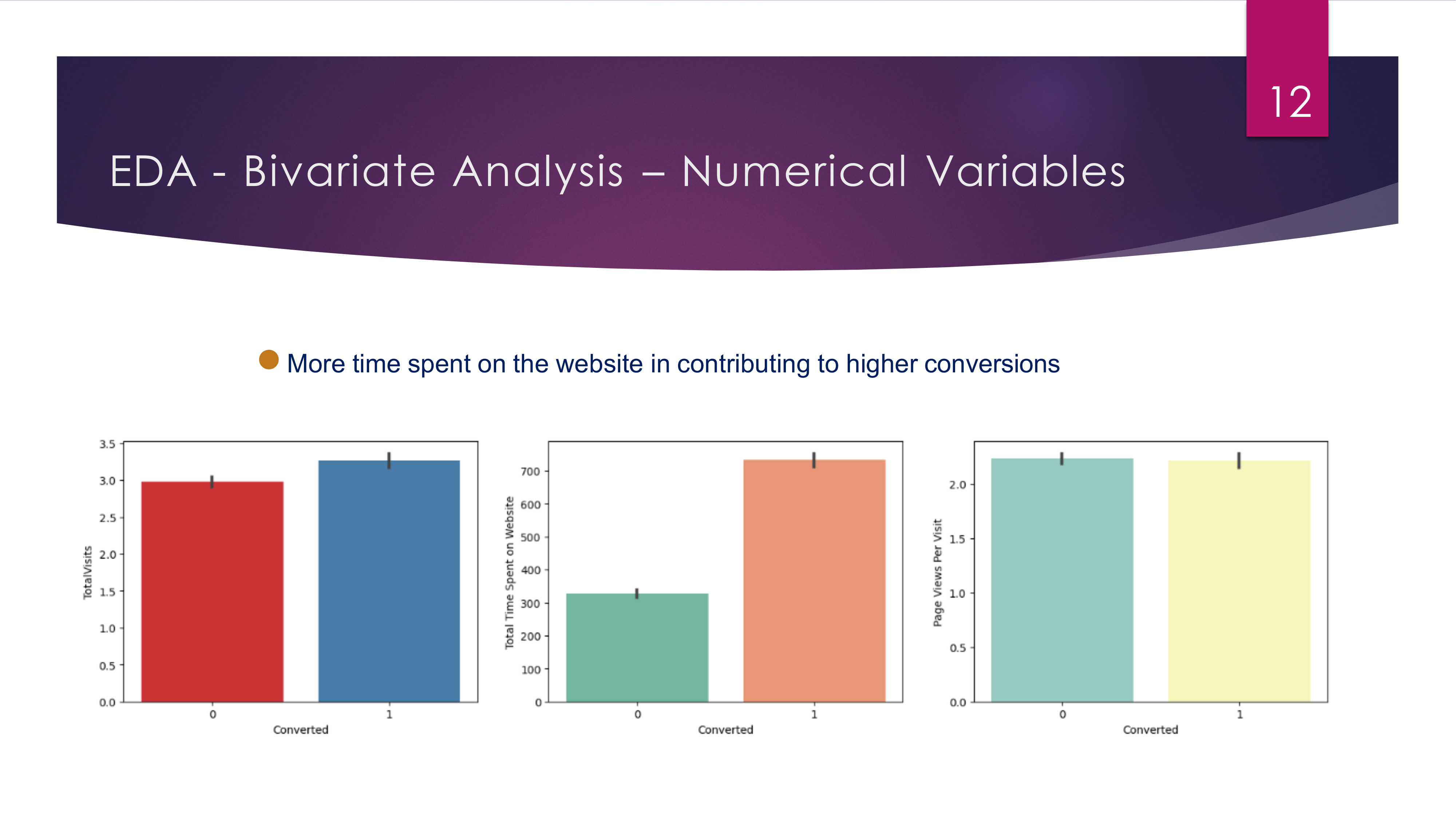
- Exploratory Data Analysis (EDA): Revealed key conversion sources such as Landing Page Submissions, Google, and Direct Traffic, as well as important factors like SMS Sent and Email Opened.
- Data Preparation: Converted categorical variables to numerical, created dummy variables, applied a 70:30 train-test split, and used MinMax scaling for logistic regression compatibility.
- Model Building: Used Recursive Feature Elimination (RFE) to select 11 significant variables and addressed multicollinearity for model stability.
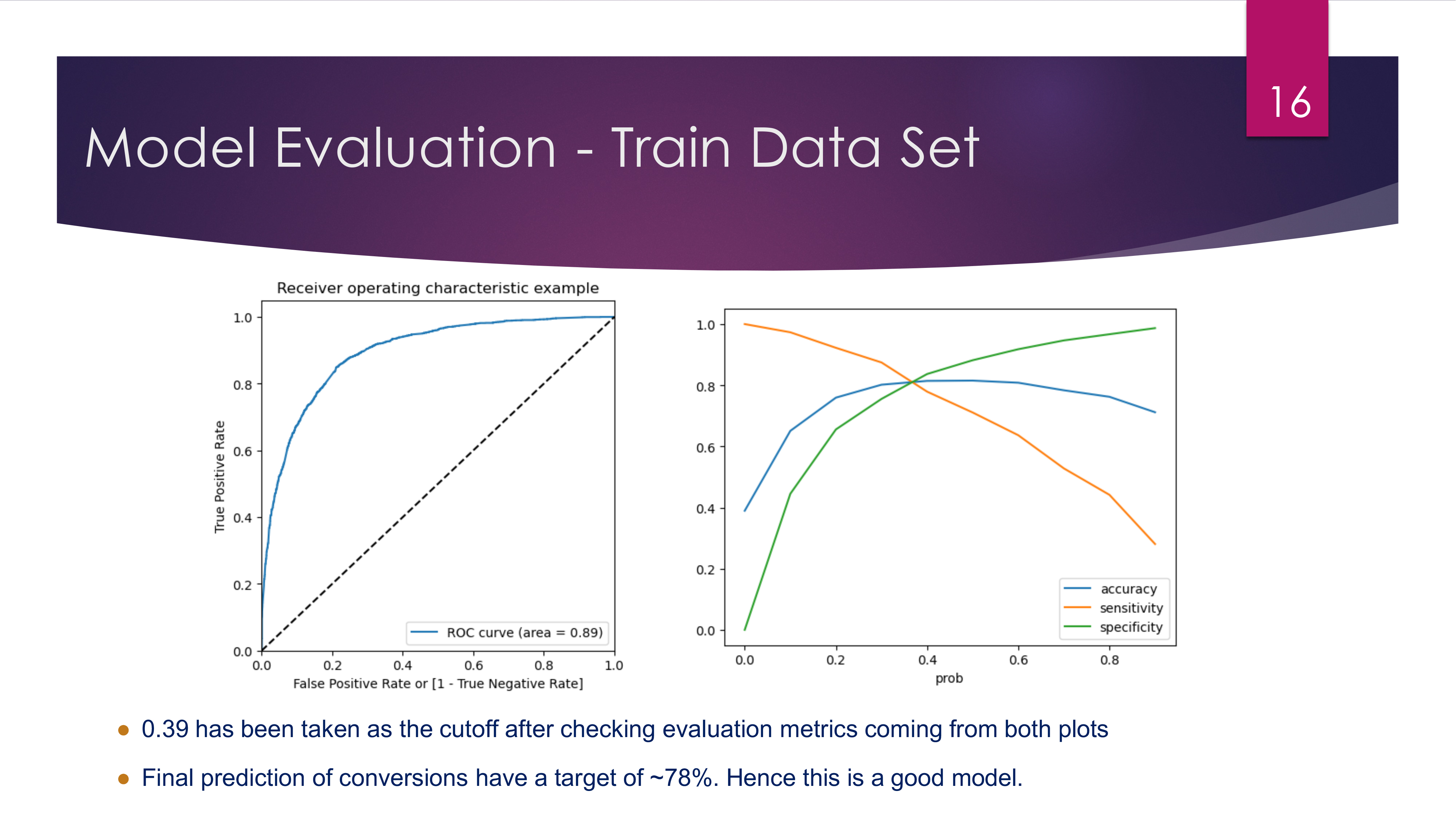
- Model Evaluation: Set a prediction threshold of 0.39, achieving accuracy of 81%, sensitivity of 77%, and specificity of 83%.
📌 Key Recommendations
- Focus on High-Score Leads: Allocate resources to leads with higher scores for better conversion rates.
- Customize Communication: Create personalized communication scripts to improve engagement.
- Improve Customer Interaction: Enhance the customer portal experience to drive more conversions.
- Explore Expansion: Utilize lead feedback and target working professionals to broaden reach.